Introduction
Depuis quelques mois, une nouvelle catégorie d'utilisateurs parcourt le web : les agents IA. Ces programmes autonomes, pilotés par des modèles de langage comme ChatGPT ou Claude, naviguent sur des sites, extraient des informations et effectuent des actions pour le compte d'utilisateurs humains. Contrairement à un navigateur classique, un agent ne "voit" pas la page : il en lit le contenu structuré, interprète les signaux mis à sa disposition, et décide de la suite à donner.
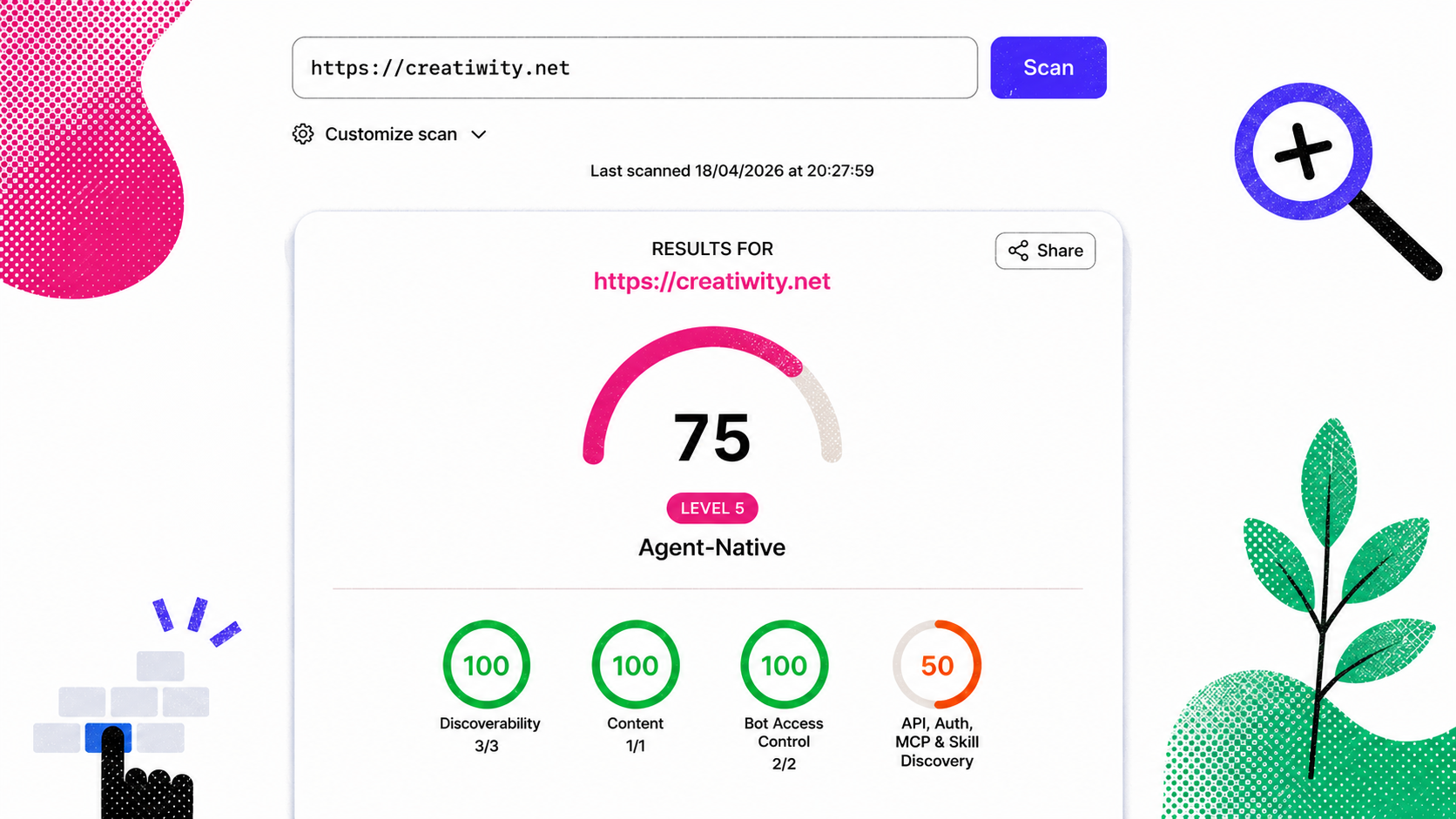
Face à cette réalité émergente, se pose une question concrète pour tout développeur ou designer web : mon site est-il lisible et utilisable par ces nouveaux interlocuteurs ? C'est précisément à cette question que répond le nouvel outil isitagentready.com proposé par Cloudflare, qui évalue l'état de préparation d'un site vis-à-vis des agents IA.
Nous avons passé notre propre site au crible de cet outil et apporté cinq améliorations ciblées. Voici le détail de notre démarche.
Qu'est-ce qu'un site "IA ready" ?
Un site "IA ready" est un site dont le contenu et les interfaces sont pensés pour être consommés aussi bien par des humains que par des agents automatisés. Cela ne signifie pas sacrifier l'expérience utilisateur classique, mais ajouter une couche de lisibilité machine par-dessus une structure web existante.
Trois axes principaux ressortent de l'évaluation d'isitagentready.com :
- La négociation de contenu : l'agent peut-il obtenir le contenu dans un format qu'il comprend facilement, comme le Markdown ?
- La découvrabilité des APIs : l'agent peut-il identifier les ressources disponibles sur le site sans avoir à explorer manuellement chaque URL ?
- Les signaux de consentement : le site indique-t-il explicitement ce que les IA sont autorisées à faire avec son contenu ?
- Un serveur MCP : le site expose-t-il un protocole standardisé permettant à n'importe quel agent d'interagir avec ses données de façon structurée ?
- Le WebMCP : les agents intégrés au navigateur peuvent-ils accéder directement aux outils du site sans passer par un serveur intermédiaire ?
1. Proposer le contenu en Markdown
Un agent IA consomme avant tout du texte structuré. Le HTML d'une page web est conçu pour être rendu visuellement : il contient des balises de mise en forme, des scripts, des styles qui n'apportent aucune valeur à un modèle de langage. Le Markdown, en revanche, conserve la structure sémantique (titres, listes, liens, blocs de code) dans un format léger et directement exploitable.
La bonne pratique consiste à détecter le header HTTP Accept: text/markdown envoyé par l'agent dans sa requête, et à retourner une version Markdown de la page plutôt que le HTML complet. C'est ce que l'on appelle la négociation de contenu.
En pratique, sur un site Nuxt, cela se met en place via un plugin Nitro qui intercepte les réponses HTML et les convertit à la volée avec une librairie comme turndown :
// server/plugins/markdown-negotiation.ts
import TurndownService from 'turndown'
export default defineNitroPlugin((nitro) => {
nitro.hooks.hook('render:response', (response, { event }) => {
const accept = getHeader(event, 'accept') || ''
if (!accept.includes('text/markdown')) {
return
}
const td = new TurndownService({ headingStyle: 'atx', codeBlockStyle: 'fenced' })
response.body = td.turndown(response.body as string)
response.headers['content-type'] = 'text/markdown; charset=utf-8'
})
})
En bonus, on peut ajouter un header X-Markdown-Tokens estimant le nombre de tokens du document — une information utile pour les agents qui gèrent un budget de contexte.
2. Faciliter la découverte des APIs
Un agent qui arrive sur une page d'accueil ne sait pas a priori quelles ressources le site expose. Pour lui faciliter la tâche, deux mécanismes complémentaires existent.
Les headers Link de découverte
À la manière des flux RSS exposés via des balises <link> dans le <head>, il est possible d'inclure dans les headers HTTP de chaque page un pointeur vers les collections de données disponibles :
Link: </.well-known/api-catalog>; rel="api-catalog",
</api/portfolio>; rel="collection"; title="Portfolio",
</api/blog/posts>; rel="collection"; title="Blog"
Un agent qui reçoit une réponse HTML peut ainsi immédiatement identifier les ressources à explorer sans avoir à analyser le DOM de la page.
Le fichier .well-known/api-catalog
La convention .well-known — déjà utilisée pour des fichiers comme robots.txt ou les certificats ACME — propose un emplacement standardisé pour décrire les APIs d'un site. Le fichier /.well-known/api-catalog retourne un JSON listant les endpoints disponibles, leur identifiant et leur description :
{
"apis": [
{
"id": "portfolio",
"title": "Portfolio API",
"description": "List of Creatiwity projects and case studies",
"urls": ["/api/portfolio"]
},
{
"id": "blog",
"title": "Blog API",
"description": "Blog posts and articles",
"urls": ["/api/blog/posts"]
}
]
}
Ce fichier constitue un point d'entrée structuré pour tout agent souhaitant interagir avec le contenu du site de façon programmatique.
3. Déclarer ses préférences de consentement
Le robots.txt est historiquement la manière standard d'indiquer aux crawlers ce qu'ils peuvent ou non explorer. Avec la montée en puissance des modèles d'IA, une nouvelle couche de signaux a émergé : les Content Signals.
Ces directives permettent d'exprimer des préférences précises sur l'utilisation qui peut être faite du contenu :
| Signal | Signification |
|---|---|
ai-train=no |
Le contenu ne doit pas être utilisé pour entraîner des modèles |
ai-input=no |
Le contenu ne doit pas être injecté en contexte dans des requêtes IA |
search=yes |
Le contenu peut être indexé pour la recherche |
Sur Nuxt, le module @nuxtjs/robots intègre nativement cette fonctionnalité via la propriété contentSignal :
// nuxt.config.ts
robots: {
groups: [
{
userAgent: ['*'],
allow: ['/'],
contentSignal: ['ai-train=no', 'search=yes', 'ai-input=no'],
},
],
},
Ces signaux ne sont pas encore des standards universellement respectés, mais ils constituent un premier geste de gouvernance du contenu vis-à-vis de l'écosystème IA — et leur adoption progresse rapidement.
4. Exposer un serveur MCP
Les trois mécanismes précédents rendent le site lisible par les agents. Le Model Context Protocol (MCP), introduit par Anthropic en 2024, va plus loin : il permet à un agent d'interagir activement avec le contenu d'un site via des outils typés, décrits et appelables à la demande.
Concrètement, un serveur MCP expose des tools — des fonctions nommées avec leurs paramètres et leur description — qu'un agent peut invoquer directement, comme il appellerait une API. La différence avec une API REST classique tient dans la découvrabilité et la description sémantique : l'agent comprend ce que fait l'outil et décide lui-même quand l'utiliser.
Sur Nuxt, le SDK officiel @modelcontextprotocol/sdk permet de monter un serveur MCP en quelques lignes via un handler Nitro. Ici, on expose par exemple les projets du portfolio et les articles du blog :
// server/routes/mcp.ts
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'
import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js'
const server = new McpServer({ name: 'creatiwity', version: '1.0.0' })
server.tool(
'list_portfolio',
'List Creatiwity portfolio projects with title, categories and URL.',
{ page: z.string().optional(), category: z.string().optional() },
async ({ page, category }) => {
const data = await $fetch(`/api/portfolio?page=${page ?? 1}`)
return { content: [{ type: 'text', text: JSON.stringify(data) }] }
},
)
Pour que les agents puissent découvrir ce serveur, on ajoute un fichier /.well-known/mcp/server-card.json indiquant l'endpoint et les capacités exposées (tools, resources, prompts).
5. Enregistrer les outils via WebMCP
Le serveur MCP couvre les agents qui se connectent depuis l'extérieur — Claude Desktop, un agent de terminal, un workflow automatisé. Mais une nouvelle catégorie d'agents émerge : ceux qui s'exécutent directement dans le navigateur, intégrés à des extensions ou au moteur du browser lui-même.
Pour ces agents, le W3C travaille sur une API native : navigator.modelContext. Baptisée WebMCP, cette interface permet à une page web d'enregistrer des outils directement auprès de l'agent du navigateur, sans appel réseau, en pur JavaScript côté client.
Sur Nuxt, cela se met en place via un plugin client qui détecte la présence de l'API et enregistre les mêmes outils que le serveur MCP :
// app/plugins/webmcp.client.ts
export default defineNuxtPlugin(() => {
const mc = navigator.modelContext
if (!mc) {
return
}
mc.registerTool({
name: 'list_portfolio',
title: 'List Portfolio Projects',
description: 'List Creatiwity portfolio projects and case studies.',
inputSchema: { type: 'object', properties: {} },
execute: async () => $fetch('/api/portfolio'),
annotations: { readOnlyHint: true },
})
})
L'annotation readOnlyHint: true indique à l'agent que l'outil ne modifie pas d'état — un signal de confiance important pour les agents qui distinguent les opérations sûres des opérations à risque.
WebMCP est encore au stade expérimental, mais anticiper son adoption garantit que le site sera prêt dès que les premiers navigateurs le supporteront nativement.
Évaluer son site avec isitagentready.com
L'outil isitagentready.com permet en quelques secondes d'obtenir un diagnostic de l'état de préparation de son site. Il teste la présence des mécanismes décrits ci-dessus — négociation Markdown, headers de découverte, signaux robots — et retourne un score accompagné de recommandations concrètes.
C'est un excellent point de départ pour prioriser ses efforts, que l'on parte de zéro ou que l'on cherche à compléter une démarche déjà engagée.
Conclusion
L'accessibilité web nous a appris qu'un site bien conçu doit être utilisable par tous, quelles que soient les conditions d'accès. L'ère des agents IA nous invite à étendre cette ambition : un site bien conçu doit désormais être lisible, structuré et gouverné pour des interlocuteurs non-humains.
Les cinq optimisations présentées ici — négociation de contenu Markdown, découverte d'APIs via headers et .well-known, signaux de consentement dans robots.txt, serveur MCP et WebMCP — sont rapides à mettre en œuvre et apportent une valeur immédiate. Comme pour l'accessibilité, mieux vaut les intégrer dès la conception que de les ajouter en bout de course.
Découvrez le score de votre site sur isitagentready.com
Sources :
- Model Context Protocol — spécification officielle — Anthropic
- IETF Draft — api-catalog well-known URI — IETF
- WebMCP est disponible en preview dans Chrome — Chrome for developers
- Content Signals pour robots.txt — content-signals.org
- Turndown — conversion HTML → Markdown
- MCP SDK TypeScript — GitHub